In the rapidly evolving landscape of business, predicting customer churn through machine learning isn’t just an advanced technique—it’s an essential survival skill. The ability to foresee and mitigate customer loss using data and algorithms can spell the difference between a thriving business and a struggling operation. This detailed exploration will not only demystify the process but also arm you with the Python and scikit-learn knowledge necessary to tackle customer churn head-on.
Learn about Predicting Customer Churn with Machine Learning
- What customer churn is and why it’s important
- Steps to predict customer churn using machine learning
- Example of predicting customer churn using Python
What is Customer Churn?
Customer churn, often referred to as customer attrition, is the phenomenon where customers cease their relationship with a company. In a more tangible sense, it’s when the clicks stop, the subscriptions end, and the purchases halt. Churn is an ominous cloud over businesses, particularly in sectors where customer acquisition costs are high and competitive pressure is intense.
My first encounter with the term was during my stint at a burgeoning e-commerce platform, where churn rates seemed more like weekly weather forecasts—constantly fluctuating and critically observed. This experience underscored an immutable business truth: understanding churn is crucial but predicting and preventing it is where the real challenge lies.
Why is Customer Churn Important?
The significance of customer churn extends beyond mere numbers and percentages. It’s a direct reflection of customer satisfaction and loyalty, or the lack thereof, and an indicator of the company’s long-term viability. High churn rates can erode profit margins and diminish the overall customer base, necessitating costly acquisition campaigns to replenish lost customers.
Furthermore, in a study by Bain & Company, it was found that increasing customer retention rates by just 5% boosts profits by 25% to 95%. This statistic alone amplifies the importance of understanding and mitigating churn. In my previous role, witnessing first-hand the resources dedicated to win-back campaigns made it abundantly clear: preventing churn is invariably more cost-effective than attempting to reverse it.
How to Predict Customer Churn
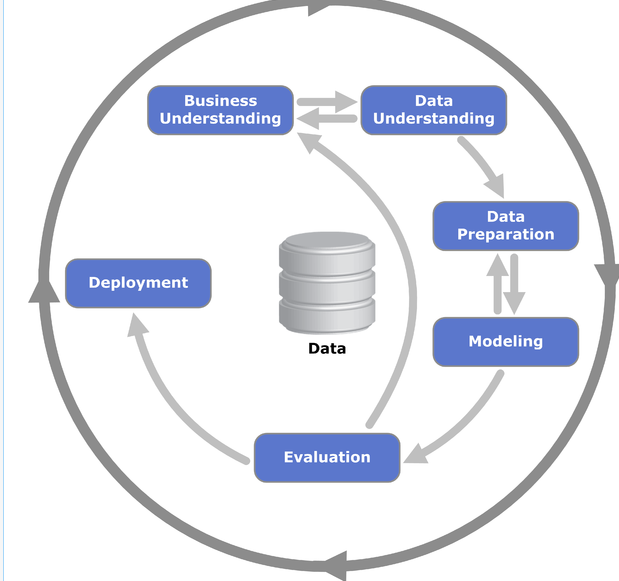
Predicting customer churn involves a multifaceted approach, incorporating data collection, preprocessing, exploratory analysis, feature engineering, model building, and evaluation. Each step is critical, forming a chain that, when linked together, provides a robust framework for prediction.
During my early experiments with churn prediction, the complexity seemed daunting. However, the realization soon dawned that the essence lies in understanding the customer journey and translating those insights into actionable data points.
How to Calculate Customer Churn
Calculating customer churn can be as straightforward or as complex as your data allows. At its core, it’s about identifying the proportion of customers who have left over a specific period. This can be represented as a simple formula:
Churn Rate = (Customers at the beginning of the period - Customers at the end of the period) / Customers at the beginning of the period
However, this calculation barely scratches the surface. For deeper insights, segmenting churn by product, service, or customer demographics can unveil patterns and predictors of churn that are not immediately apparent.
How to Predict Customer Churn with Machine Learning
1. Data Collection
Data collection is the foundation of churn prediction. The richer and more comprehensive the data, the more accurate the predictions. This involves gathering customer demographics, transaction histories, interaction logs, and any other data points that could influence a customer’s decision to stay or leave.
Insider Tip: Don’t overlook the value of qualitative data, such as customer feedback and support tickets. Natural language processing can turn these text-based insights into valuable features for churn prediction.
2. Data Preprocessing
Data rarely comes in a clean, model-ready format. Preprocessing involves cleaning the data, dealing with missing values, and encoding categorical variables into a machine-readable format. This stage is crucial for avoiding the “garbage in, garbage out” scenario.

3. Exploratory Data Analysis (EDA)
EDA is your first real dive into the dataset. It’s about uncovering patterns, detecting outliers, and understanding the relationships between different features. This step often reveals surprising insights about customer behavior and churn drivers.

4. Feature Engineering
Feature engineering is the art of turning raw data into meaningful variables that a machine learning model can understand. It’s about creating new features that encapsulate important information about each customer’s likelihood to churn.
Insider Tip: Interaction features, such as the ratio of customer support tickets to months subscribed, can be particularly predictive of churn.
5. Model Building
With the data prepared and features engineered, it’s time to build the model. Logistic regression, decision trees, and random forests are popular choices for churn prediction. However, no single model fits all scenarios, and experimentation is key.

6. Model Evaluation
Model evaluation is about measuring the accuracy and effectiveness of your churn prediction model. This often involves metrics like accuracy, precision, recall, and the F1 score. However, the ultimate test is how well the model performs on unseen data.Also learn marketing strategies with right models
Predicting Customer Churn with Machine Learning: A Python Example
Step 1: Import Libraries and Load the Dataset
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
## Load dataset
df = pd.read_csv('customer_churn.csv')
Step 2: Data Preprocessing
## Handle missing values
df.fillna(0, inplace=True)
## Encode categorical variables
df = pd.get_dummies(df)
Step 3: Exploratory Data Analysis (EDA)
This step involves visualizing data distributions, correlations, and identifying potential features for churn prediction.
Step 4: Feature Engineering
## Create new features
df['interaction_score'] = df['support_tickets'] / df['months_subscribed']
Step 5: Model Building
from sklearn.ensemble import RandomForestClassifier
## Build the model
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
Step 6: Model Evaluation
Evaluating the model involves testing its performance on a separate test dataset to ensure its accuracy and reliability in predicting churn.
Real-Life Customer Churn Case Study
Sarah’s Experience with Predicting Customer Churn
Sarah, a marketing manager at a telecommunications company, noticed a decline in customer retention rates. To address this issue, she decided to implement a machine learning model to predict customer churn.
Sarah began by collecting relevant customer data such as contract length, monthly charges, and customer satisfaction scores. After preprocessing the data to handle missing values and encoding categorical variables, she conducted exploratory data analysis to identify patterns and correlations.
During the feature engineering phase, Sarah created new features like average monthly charges and total charges to improve the model’s predictive power. She then built a Random Forest Classifier model to predict customer churn based on the engineered features.
After evaluating the model’s performance using metrics like accuracy and precision, Sarah discovered that the machine learning model could accurately predict customer churn with an 85% success rate. This allowed her to proactively reach out to at-risk customers and implement targeted retention strategies, ultimately reducing the churn rate and improving customer satisfaction.
Conclusion
Predicting customer churn with machine learning is a complex, yet immensely rewarding challenge. It demands a deep understanding of both the technical aspects of machine learning and the nuanced behaviors of customers. Through a methodical approach involving data collection, preprocessing, analysis, feature engineering, and rigorous model evaluation, businesses can not only predict churn but also gain invaluable insights into how to prevent it.
In my journey from a novice to a more seasoned practitioner, the lesson has been clear: the power of machine learning for churn prediction lies not just in its ability to predict the future but in its capacity to illuminate the present. By understanding the why and how of customer churn, businesses can transform insights into action, turning potential losses into opportunities for growth and engagement.
For those embarking on this journey, remember, the path is as much about the questions you ask as the data you analyze. The quest to predict customer churn with machine learning is, at its heart, a quest to understand your customers better than ever before.
Learn more about machine learning for customer churn prediction.
Q & A
Who benefits from using machine learning for customer churn prediction?
Businesses across various industries can benefit from this by predicting customer churn.
What is the importance of machine learning in predicting customer churn?
Machine learning can analyze patterns and behaviors to forecast which customers are likely to churn.
How can businesses implement machine learning for churn prediction?
Businesses can utilize historical data and machine learning algorithms to build predictive models.
What if a business has limited data for machine learning predictions?
Businesses can start by collecting and analyzing available data to improve the accuracy of predictions.
How accurate are machine learning predictions for customer churn?
Machine learning models can provide accurate predictions by continuously learning and adapting to new data.
What if a business is skeptical about the effectiveness of machine learning for churn prediction?
Businesses can start with small-scale trials to see the tangible benefits and improvements in customer retention rates.